* Add normalization processor and related components - Introduced `NormalizationProcessor` to handle both observation normalization and action unnormalization. - Added `ObservationNormalizer` and `ActionUnnormalizer` classes for specific normalization tasks. - Updated `__init__.py` to include the new `NormalizationProcessor` in the module exports. - Enhanced `ObservationProcessor` with registration in the `ProcessorStepRegistry` for better modularity. - Created `RenameProcessor` for renaming keys in observations, improving flexibility in data processing. * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Enhance processing architecture with new components - Added `RenameProcessor` to facilitate key renaming in observations, improving data handling flexibility. - Updated `__init__.py` to include `RenameProcessor` in module exports. - Refactored `NormalizationProcessor` and `ObservationNormalizer` to use `rsplit` for better key handling. - Introduced comprehensive tests for `NormalizationProcessor` and `RenameProcessor` to ensure functionality and robustness. * chore (docs): add docstring for processor * fix (test): test factory * fix(test): policies * Update tests/processor/test_observation_processor.py Co-authored-by: Copilot <175728472+Copilot@users.noreply.github.com> Signed-off-by: Adil Zouitine <adilzouitinegm@gmail.com> * chore(test): add suggestion made by copilot regarding numpy test * fix(test): import issue * Refactor normalization components and update tests - Renamed `ObservationNormalizer` to `NormalizerProcessor` and `ActionUnnormalizer` to `UnnormalizerProcessor` for clarity. - Consolidated normalization logic for both observations and actions into `NormalizerProcessor` and `UnnormalizerProcessor`. - Updated tests to reflect the new class names and ensure proper functionality of normalization and unnormalization processes. - Enhanced handling of missing statistics in normalization processes. * chore (docstrin):Improve docstring for NormalizerProcessor * feat (device processor): Implement device processor * chore (batch handling): Enhance processing components with batch conversion utilities * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix(test): linting issue * chore (output format): improves output format * chore (type): add typing for multiprocess envs * feat (overrides): Implement support for loading processors with parameter overrides - Added the ability to provide non-serializable objects when loading processors from saved configurations using the `overrides` parameter. - Enhanced error handling for invalid override keys and instantiation errors. - Updated documentation and examples to illustrate the usage of overrides for both registered and unregistered steps. - Added comprehensive tests to validate the new functionality and ensure backward compatibility. * chore(normalization): addressing comments from copilot * chore(learner): nit comment from copilot * feat(pipeline): Enhance step_through method to support both tuple and dict inputs * refactor(pipeline): Simplify observation and padding data handling in batch transitions * Apply suggestions from code review Co-authored-by: Simon Alibert <75076266+aliberts@users.noreply.github.com> Signed-off-by: Adil Zouitine <adilzouitinegm@gmail.com> * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * refactor(pipeline): Introduce ComplementaryDataProcessor for handling complementary data in transitions * fix(ci): temporary fix on dataset deps version * feat(processors): Introduce processors for various policy types - Added `make_processor` function to create processor instances for different policy types, including `tdmpc`, `diffusion`, `act`, `vqbet`, `pi0`, `pi0fast`, `sac`, and `reward_classifier`. - Implemented corresponding processor files for each policy type, encapsulating normalization and unnormalization steps. - Updated existing policies to remove direct normalization dependencies, enhancing modularity and clarity. - Enhanced test coverage to validate the integration of new processors with existing policy configurations. * refactor(learner): Remove normalization from cached image features retrieval - Simplified the retrieval of observation features by removing the normalization step from the `get_cached_image_features` method calls. - This change enhances clarity and aligns with the recent updates to policy processors. * refactor(policies): Remove unnormalization step from action predictions - Eliminated the unnormalization of actions in both `TDMPCPolicy` and `VQBeTPolicy` classes to streamline action prediction. - This change improves code clarity and aligns with recent updates to policy processors. * feat(train): Integrate preprocessor into training pipeline * refactor(train): Update preprocessor initialization to include dataset statistics * refactor(policies): Enhance processor creation and add NaN detection hook * refactor(train): Update memory pinning logic for mps compatibility * feat: initial commit phone teleop * ugly delta control * use quaternion * Refactor observation preprocessing to use a modular pipeline system - Introduced `RobotPipeline` and `ObservationProcessor` for handling observation transformations. - Updated `preprocess_observation` to maintain backward compatibility while leveraging the new pipeline. - Added tests for the new processing components and ensured they match the original functionality. - Removed hardcoded logic in favor of a more flexible, composable architecture. * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Refactor observation processing and improve modularity - Updated `ObservationProcessor` to enhance the modular design for processing observations. - Cleaned up imports and improved code readability by removing unnecessary lines and comments. - Ensured backward compatibility while integrating new processing components. - Added tests to validate the functionality of the updated processing architecture. * Remove redundant tests for None observation and serialization methods in `test_observation_processor.py` to streamline the test suite and improve maintainability. * Refactor processing architecture to use RobotProcessor - Replaced instances of RobotPipeline with RobotProcessor across the codebase for improved modularity and clarity. - Introduced ProcessorStepRegistry for better management of processing steps. - Updated relevant documentation and tests to reflect the new processing structure. - Enhanced the save/load functionality to support the new processor design. - Added a model card template for RobotProcessor to facilitate sharing and documentation. * Add RobotProcessor tutorial to documentation - Introduced a new tutorial on using RobotProcessor for preprocessing robot data. - Added a section in the table of contents for easy navigation to the new tutorial. - The tutorial covers key concepts, real-world scenarios, and practical examples for effective use of the RobotProcessor pipeline. * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Add normalization processor and related components - Introduced `NormalizationProcessor` to handle both observation normalization and action unnormalization. - Added `ObservationNormalizer` and `ActionUnnormalizer` classes for specific normalization tasks. - Updated `__init__.py` to include the new `NormalizationProcessor` in the module exports. - Enhanced `ObservationProcessor` with registration in the `ProcessorStepRegistry` for better modularity. - Created `RenameProcessor` for renaming keys in observations, improving flexibility in data processing. * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * Enhance processing architecture with new components - Added `RenameProcessor` to facilitate key renaming in observations, improving data handling flexibility. - Updated `__init__.py` to include `RenameProcessor` in module exports. - Refactored `NormalizationProcessor` and `ObservationNormalizer` to use `rsplit` for better key handling. - Introduced comprehensive tests for `NormalizationProcessor` and `RenameProcessor` to ensure functionality and robustness. * chore (docs): add docstring for processor * fix (test): test factory * fix(test): policies * Update tests/processor/test_observation_processor.py Co-authored-by: Copilot <175728472+Copilot@users.noreply.github.com> Signed-off-by: Adil Zouitine <adilzouitinegm@gmail.com> * chore(test): add suggestion made by copilot regarding numpy test * fix(test): import issue * Refactor normalization components and update tests - Renamed `ObservationNormalizer` to `NormalizerProcessor` and `ActionUnnormalizer` to `UnnormalizerProcessor` for clarity. - Consolidated normalization logic for both observations and actions into `NormalizerProcessor` and `UnnormalizerProcessor`. - Updated tests to reflect the new class names and ensure proper functionality of normalization and unnormalization processes. - Enhanced handling of missing statistics in normalization processes. * chore (docstrin):Improve docstring for NormalizerProcessor * feat (device processor): Implement device processor * chore (batch handling): Enhance processing components with batch conversion utilities * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix(test): linting issue * chore (output format): improves output format * chore (type): add typing for multiprocess envs * feat (overrides): Implement support for loading processors with parameter overrides - Added the ability to provide non-serializable objects when loading processors from saved configurations using the `overrides` parameter. - Enhanced error handling for invalid override keys and instantiation errors. - Updated documentation and examples to illustrate the usage of overrides for both registered and unregistered steps. - Added comprehensive tests to validate the new functionality and ensure backward compatibility. * chore(normalization): addressing comments from copilot * chore(learner): nit comment from copilot * feat(pipeline): Enhance step_through method to support both tuple and dict inputs * refactor(pipeline): Simplify observation and padding data handling in batch transitions * Apply suggestions from code review Co-authored-by: Simon Alibert <75076266+aliberts@users.noreply.github.com> Signed-off-by: Adil Zouitine <adilzouitinegm@gmail.com> * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * refactor(pipeline): Introduce ComplementaryDataProcessor for handling complementary data in transitions * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * refactor(pipeline): Transition from tuple to dictionary format for EnvTransition - Updated the EnvTransition structure to use a dictionary format instead of a tuple, enhancing readability and maintainability. - Replaced instances of TransitionIndex with TransitionKey for accessing transition components. - Adjusted related processing functions and tests to accommodate the new dictionary format, ensuring consistent handling of transitions across the codebase. * refactor(observation_processor): Improve observation processing by using constants and simplifying pixel handling - Introduced constants for observation keys to enhance readability. - Streamlined the handling of the "pixels" key by copying observations first and processing images more clearly. - Updated the environment state and agent position assignments to use the new constants, improving maintainability. * feat(pipeline): Add hook unregistration functionality and enhance documentation - Implemented methods to unregister before, after, and reset hooks in the RobotProcessor class, allowing for more flexible hook management. - Enhanced documentation to clarify hook execution semantics and the implications of modifying transitions within hooks. - Added comprehensive tests to verify the correct behavior of hook registration and unregistration, including error handling for non-existent hooks. * refactor(pipeline): Clarify hook behavior and improve documentation - Updated the RobotProcessor class to ensure hooks are strictly for observation and do not modify transitions, enhancing clarity and maintainability. - Refactored hook registration methods to reflect the new behavior, ensuring they accept only functions that do not return modified transitions. - Enhanced documentation to clearly outline the purpose of hooks and their execution semantics. - Added tests to verify that hooks are not executed during the step_through method while ensuring they function correctly during the __call__ method. * feat(pipeline): Add __repr__ method to RobotProcessor for improved readability - Implemented a __repr__ method in the RobotProcessor class to provide a clear string representation of the processor, including step names and optional parameters like name and seed. - Added comprehensive tests to validate the __repr__ output for various scenarios, including empty processors, single and multiple steps, custom names, and seed values. - Ensured that the representation handles long lists of steps with truncation for better readability. * chore(pipeline): Move _CFG_NAME along other class member * refactor(pipeline): Utilize get_safe_torch_device for device assignment - Replaced direct torch.device instantiation with get_safe_torch_device to ensure safe device handling. - This change enhances code readability and maintains consistency in device management across the RobotProcessor class. * refactor(pipeline): Enhance state filename generation and profiling method - Updated state filename generation to use the registry name when available, improving clarity in saved files. - Modified the profile_steps method to include a warmup_runs parameter, allowing for more controlled performance profiling. - Ensured consistent conditions during profiling by deep copying transitions for each run, enhancing accuracy in timing results. * chore(doc): address pip install commant lerobot that not exist yet * feat(pipeline): Enhance configuration filename handling and state file naming - Introduced support for custom configuration filenames in the `save_pretrained` method, allowing users to specify a filename instead of the default. - Improved state file naming to include step indices, preventing conflicts when multiple processors of the same type are saved. - Added automatic detection for configuration files when loading from a directory, with error handling for multiple files. - Updated tests to validate new features, including custom filenames and automatic config detection. * refactor(pipeline): Improve state file naming conventions for clarity and uniqueness - Enhanced state file naming to include the processor's sanitized name, ensuring uniqueness when multiple processors are saved in the same directory. - Updated tests to reflect changes in state file naming, verifying that filenames now include the processor name and step indices to prevent conflicts. - Added a new test to validate state file naming when using multiple processors, ensuring distinct filenames for each processor's state files. * docs(pipeline): Add clarification for repo name sanitization process * feat(processors): Introduce processors for various policy types - Added `make_processor` function to create processor instances for different policy types, including `tdmpc`, `diffusion`, `act`, `vqbet`, `pi0`, `pi0fast`, `sac`, and `reward_classifier`. - Implemented corresponding processor files for each policy type, encapsulating normalization and unnormalization steps. - Updated existing policies to remove direct normalization dependencies, enhancing modularity and clarity. - Enhanced test coverage to validate the integration of new processors with existing policy configurations. * refactor(learner): Remove normalization from cached image features retrieval - Simplified the retrieval of observation features by removing the normalization step from the `get_cached_image_features` method calls. - This change enhances clarity and aligns with the recent updates to policy processors. * refactor(policies): Remove unnormalization step from action predictions - Eliminated the unnormalization of actions in both `TDMPCPolicy` and `VQBeTPolicy` classes to streamline action prediction. - This change improves code clarity and aligns with recent updates to policy processors. * feat(train): Integrate preprocessor into training pipeline * refactor(train): Update preprocessor initialization to include dataset statistics * refactor(policies): Enhance processor creation and add NaN detection hook * feat(record): Integrate RobotProcessor into recording loop and update policy handling - Added support for RobotProcessor in the record_loop function to enhance data processing capabilities. - Updated the logic to reset both policy and processor when provided, ensuring proper state management. - Modified action prediction to utilize the processor, improving the overall functionality of the recording process. - Adjusted the save_checkpoint function to include preprocessor state saving, enhancing checkpointing capabilities. * feat(migration): Add script for migrating policy models with normalization layers * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * feat(migrate): Enhance migration script to create preprocessor and postprocessor for policy models - Updated the migration script to generate both a preprocessor and a postprocessor, improving the handling of normalization for training and inference. - Added functionality to convert features to PolicyFeature objects, ensuring compatibility with the new processor architecture. - Refined the extraction and removal of normalization statistics and layers, streamlining the migration process. - Improved error handling for missing mandatory configuration fields during model instantiation. * feat(migrate): Add model card generation and saving to migration script - Implemented functionality to generate and save a model card for the migrated model, including metadata such as dataset repository ID, license, and tags. - Enhanced the script to push the model card to the hub if requested, improving model documentation and accessibility. - Refactored the saving process to ensure the model card is saved locally and uploaded correctly when pushing to the hub. * feat(processor): Introduce ToBatchProcessor for handling observation batching - Added ToBatchProcessor to ensure observations have proper batch dimensions for model processing. - Implemented functionality to add batch dimensions to state and image observations as needed. - Created comprehensive unit tests to validate the processor's behavior with various tensor dimensions and types. - Ensured compatibility with existing transition keys and maintained the integrity of non-observation data. * feat(processors): Add ToBatchProcessor to multiple policy processors - Integrated ToBatchProcessor into various policy processors to handle observation batching. - Updated make functions for act, diffusion, pi0, pi0fast, sac, smolvla, tdmpc, and vqbet processors to include the new batching functionality. - Ensured consistency across all processor implementations for improved data handling. * refactor(factory): Remove unused imports and NaN detection hook from processor creation * feat(batch_processor): Enhance ToBatchProcessor to handle action batching - Updated ToBatchProcessor to add batch dimensions to actions in addition to observations. - Implemented separate methods for processing observations and actions, improving code readability. - Added comprehensive unit tests to validate action batching functionality across various tensor dimensions and types. * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * feat(factory): Enhance make_processor to support preprocessor and postprocessor configuration - Introduced ProcessorConfigKwargs TypedDict for better type safety in processor configuration. - Updated make_processor to accept preprocessor and postprocessor configuration filenames, improving flexibility in processor instantiation. - Refactored the loading of pretrained processors to utilize the new configuration options. * refactor(factory): Clean up imports in factory.py - Removed unused import of IdentityProcessor to streamline the code. * feat(migrate): Extend load_model_from_hub to include train configuration - Updated load_model_from_hub to return the train configuration alongside the model state_dict and config. - Modified main function to handle the additional train configuration when loading models from both the hub and local paths. - Adjusted dataset_repo_id extraction to utilize the train configuration for improved accuracy. * refactor(record): Rename processor parameters and update processing logic - Renamed `processor` to `preprocessor` and added `postprocessor` parameter for clarity. - Updated the `record_loop` and `predict_action` functions to utilize the new preprocessor and postprocessor, enhancing the processing flow. - Ensured compatibility with existing functionality while improving code readability. * feat(batch_processor): Add task field processing to ToBatchProcessor - Enhanced ToBatchProcessor to wrap string tasks in a list, adding batch dimensions for compatibility with model inference. - Implemented a new method for processing complementary data, ensuring that task values are correctly handled as either strings or lists of strings. - Added comprehensive unit tests to validate task processing, including edge cases and in-place mutation of complementary data. * feat(normalization): Implement IDENTITY mode for normalization and unnormalization - Enhanced NormalizerProcessor and UnnormalizerProcessor to support IDENTITY mode, allowing features to bypass normalization when specified. - Updated processing logic to check normalization modes and handle missing statistics gracefully. - Added comprehensive unit tests to validate IDENTITY mode functionality for both observations and actions, ensuring correct behavior across various scenarios. - Improved error handling for unsupported normalization modes. * fix(rebase): remove residual normalization layer: * refactor(diffusion): remove normalization layer from input processing * Add debug + calib * cleanup * Add pipeline * fix int * Add record example * nit * Add feature contract to pipelinestep and pipeline * Add tests * Add processor tests * PR feedback * encorperate pr feedback * type in doc * oops * cleaned up steps and integrated pipeline with feature_contract * refactor steps and robot to pipeline * cleanup pipeline * cleanup code further * make it run * feat(processors): Introduce processors for various policy types - Added `make_processor` function to create processor instances for different policy types, including `tdmpc`, `diffusion`, `act`, `vqbet`, `pi0`, `pi0fast`, `sac`, and `reward_classifier`. - Implemented corresponding processor files for each policy type, encapsulating normalization and unnormalization steps. - Updated existing policies to remove direct normalization dependencies, enhancing modularity and clarity. - Enhanced test coverage to validate the integration of new processors with existing policy configurations. * refactor(learner): Remove normalization from cached image features retrieval - Simplified the retrieval of observation features by removing the normalization step from the `get_cached_image_features` method calls. - This change enhances clarity and aligns with the recent updates to policy processors. * refactor(policies): Remove unnormalization step from action predictions - Eliminated the unnormalization of actions in both `TDMPCPolicy` and `VQBeTPolicy` classes to streamline action prediction. - This change improves code clarity and aligns with recent updates to policy processors. * feat(train): Integrate preprocessor into training pipeline * refactor(train): Update preprocessor initialization to include dataset statistics * refactor(policies): Enhance processor creation and add NaN detection hook * feat(record): Integrate RobotProcessor into recording loop and update policy handling - Added support for RobotProcessor in the record_loop function to enhance data processing capabilities. - Updated the logic to reset both policy and processor when provided, ensuring proper state management. - Modified action prediction to utilize the processor, improving the overall functionality of the recording process. - Adjusted the save_checkpoint function to include preprocessor state saving, enhancing checkpointing capabilities. * feat(migration): Add script for migrating policy models with normalization layers * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * feat(migrate): Enhance migration script to create preprocessor and postprocessor for policy models - Updated the migration script to generate both a preprocessor and a postprocessor, improving the handling of normalization for training and inference. - Added functionality to convert features to PolicyFeature objects, ensuring compatibility with the new processor architecture. - Refined the extraction and removal of normalization statistics and layers, streamlining the migration process. - Improved error handling for missing mandatory configuration fields during model instantiation. * feat(migrate): Add model card generation and saving to migration script - Implemented functionality to generate and save a model card for the migrated model, including metadata such as dataset repository ID, license, and tags. - Enhanced the script to push the model card to the hub if requested, improving model documentation and accessibility. - Refactored the saving process to ensure the model card is saved locally and uploaded correctly when pushing to the hub. * feat(processor): Introduce ToBatchProcessor for handling observation batching - Added ToBatchProcessor to ensure observations have proper batch dimensions for model processing. - Implemented functionality to add batch dimensions to state and image observations as needed. - Created comprehensive unit tests to validate the processor's behavior with various tensor dimensions and types. - Ensured compatibility with existing transition keys and maintained the integrity of non-observation data. * feat(processors): Add ToBatchProcessor to multiple policy processors - Integrated ToBatchProcessor into various policy processors to handle observation batching. - Updated make functions for act, diffusion, pi0, pi0fast, sac, smolvla, tdmpc, and vqbet processors to include the new batching functionality. - Ensured consistency across all processor implementations for improved data handling. * refactor(factory): Remove unused imports and NaN detection hook from processor creation * feat(batch_processor): Enhance ToBatchProcessor to handle action batching - Updated ToBatchProcessor to add batch dimensions to actions in addition to observations. - Implemented separate methods for processing observations and actions, improving code readability. - Added comprehensive unit tests to validate action batching functionality across various tensor dimensions and types. * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * feat(factory): Enhance make_processor to support preprocessor and postprocessor configuration - Introduced ProcessorConfigKwargs TypedDict for better type safety in processor configuration. - Updated make_processor to accept preprocessor and postprocessor configuration filenames, improving flexibility in processor instantiation. - Refactored the loading of pretrained processors to utilize the new configuration options. * refactor(factory): Clean up imports in factory.py - Removed unused import of IdentityProcessor to streamline the code. * feat(migrate): Extend load_model_from_hub to include train configuration - Updated load_model_from_hub to return the train configuration alongside the model state_dict and config. - Modified main function to handle the additional train configuration when loading models from both the hub and local paths. - Adjusted dataset_repo_id extraction to utilize the train configuration for improved accuracy. * refactor(record): Rename processor parameters and update processing logic - Renamed `processor` to `preprocessor` and added `postprocessor` parameter for clarity. - Updated the `record_loop` and `predict_action` functions to utilize the new preprocessor and postprocessor, enhancing the processing flow. - Ensured compatibility with existing functionality while improving code readability. * feat(batch_processor): Add task field processing to ToBatchProcessor - Enhanced ToBatchProcessor to wrap string tasks in a list, adding batch dimensions for compatibility with model inference. - Implemented a new method for processing complementary data, ensuring that task values are correctly handled as either strings or lists of strings. - Added comprehensive unit tests to validate task processing, including edge cases and in-place mutation of complementary data. * feat(normalization): Implement IDENTITY mode for normalization and unnormalization - Enhanced NormalizerProcessor and UnnormalizerProcessor to support IDENTITY mode, allowing features to bypass normalization when specified. - Updated processing logic to check normalization modes and handle missing statistics gracefully. - Added comprehensive unit tests to validate IDENTITY mode functionality for both observations and actions, ensuring correct behavior across various scenarios. - Improved error handling for unsupported normalization modes. * fix(rebase): remove residual normalization layer: * refactor(diffusion): remove normalization layer from input processing * refactor(normalization): Remove unused state dict transformation methods and streamline imports - Eliminated the _transform_state_dict_keys and _load_as_safetensor methods from PI0Policy, simplifying the model loading process. - Cleaned up imports in modeling_pi0.py by removing log_model_loading_keys and init_logging. - Updated TDMPCPolicy and VQBeTPolicy to handle action removal from batches during offline evaluation. - Introduced hotswap_stats function in normalize_processor.py to update normalization statistics dynamically, with corresponding tests to ensure functionality. * refactor(normalization): Clean up imports in normalize_processor.py * feat(batch_processor): Add feature_contract method to ToBatchProcessor - Introduced feature_contract method that returns features without modification, maintaining the no-op behavior of the processor. - This addition enhances the flexibility of the ToBatchProcessor for future feature processing needs. * fix(dependencies): Update transformers dependency constraint to allow only versions up to 4.52.0 * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * feat(tokenizer): Introduce TokenizerProcessor for text tokenization - Added TokenizerProcessor class to handle tokenization of task strings using Hugging Face's AutoTokenizer. - Supports both string and list inputs, with customizable parameters for task key, output key, and tokenization settings. - Implemented comprehensive unit tests to validate functionality, including handling of various input scenarios and integration with RobotProcessor. - Updated types.py to include LANGUAGE feature type and modified __init__.py to register the new processor. * feat(language): Enhance language processing in TokenizerProcessor - Added OBS_LANGUAGE constant to define the observation language key. - Updated TokenizerProcessor to store tokenized task data in the observation dictionary, ensuring compatibility with the new language feature. - Introduced Pi0NewLineProcessor to append newlines to tasks for proper tokenization. - Modified tests to validate the integration of language tokens and attention masks in the observation structure. * feat(tokenizer): Add padding configuration to TokenizerProcessor - Introduced `padding_side` parameter to the TokenizerProcessor for customizable padding direction. - Updated the `make_pi0_processor` function to include the new padding configuration. - Enhanced unit tests to validate the functionality of the `padding_side` parameter in various scenarios. * feat(processor): Add state management methods to Pi0NewLineProcessor * feat(normalization): Track normalization and unnormalization info in complementary data - Updated NormalizerProcessor and UnnormalizerProcessor to accept additional parameters for tracking normalization modes. - Enhanced the __call__ methods to store normalization and unnormalization information in the complementary data of transitions. - Added unit tests to verify the correct tracking of normalization info, including scenarios with missing stats and selective normalization keys. * feat(factory): Add preprocessor and postprocessor overrides to ProcessorConfigKwargs - Updated ProcessorConfigKwargs to include optional overrides for preprocessor and postprocessor configurations. - Enhanced the make_processor function to utilize the new overrides, allowing for more flexible processor initialization. * feat(processors): Integrate RenameProcessor into various processor configurations - Added RenameProcessor to the input steps of multiple processor functions, including make_act_processor, make_diffusion_processor, make_pi0_processor, make_sac_processor, make_tdmpc_processor, make_vqbet_processor, and make_smolvla_processor. - Consolidated normalization features from input and output into a single NormalizerProcessor for improved efficiency. - Updated the input steps to ensure compatibility with the new RenameProcessor integration. * Do some todos and cleanup * change feature_contract to dataset_features * use one method for conversion pipeline output to add_frame dict and use base processors where possible * Add back in and use record_loop * update todo * rename to_dataset_frame * feat(smolvla): Refactor language processing and introduce new line processor (#1658) - Removed the prepare_language method and directly accessed language tokens and masks from the batch using the OBS_LANGUAGE constant. - Added SmolVLANewLineProcessor to ensure tasks end with a newline, enhancing tokenization compatibility. - Updated the make_smolvla_processor function to include the new line processor and tokenizer processor for improved input handling. * feat(processors): Integrate DeviceProcessor into multiple processor configurations - Added DeviceProcessor to the input and output steps of various processor functions, including make_act_processor, make_diffusion_processor, make_pi0_processor, make_pi0fast_processor, make_sac_processor, make_tdmpc_processor, make_vqbet_processor, and make_smolvla_processor. - Enhanced the DeviceProcessor class with state management methods and ensured compatibility with existing processor pipelines. - Introduced unit tests for DeviceProcessor to validate functionality across different scenarios, including CPU and CUDA operations. * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * fix * fix reference frame * refactor(pipeline): Remove to() method for device management - Eliminated the to() method from RobotProcessor, which was responsible for moving tensor states to specified devices. - Removed associated unit tests that validated the functionality of the to() method across various scenarios. - Streamlined the pipeline code by focusing on other device management strategies. * feat(processor): Enhance DeviceProcessor with float dtype conversion - Added support for optional float dtype conversion in DeviceProcessor, allowing tensors to be converted to specified floating-point types while preserving non-float types. - Implemented validation for float dtype input and updated the processor's configuration methods to include float dtype. - Refactored tensor processing logic to streamline device movement and dtype conversion. - Introduced comprehensive unit tests to validate the new float dtype functionality across various scenarios. * update data visualization * update teleop example * fix record bugs * Add replay * Not code * feature(pipeline): port tokenizer pipeline for VLA (#1645) * feat(tokenizer): Introduce TokenizerProcessor for text tokenization - Added TokenizerProcessor class to handle tokenization of task strings using Hugging Face's AutoTokenizer. - Supports both string and list inputs, with customizable parameters for task key, output key, and tokenization settings. - Implemented comprehensive unit tests to validate functionality, including handling of various input scenarios and integration with RobotProcessor. - Updated types.py to include LANGUAGE feature type and modified __init__.py to register the new processor. * feat(language): Enhance language processing in TokenizerProcessor - Added OBS_LANGUAGE constant to define the observation language key. - Updated TokenizerProcessor to store tokenized task data in the observation dictionary, ensuring compatibility with the new language feature. - Introduced Pi0NewLineProcessor to append newlines to tasks for proper tokenization. - Modified tests to validate the integration of language tokens and attention masks in the observation structure. * feat(tokenizer): Add padding configuration to TokenizerProcessor - Introduced `padding_side` parameter to the TokenizerProcessor for customizable padding direction. - Updated the `make_pi0_processor` function to include the new padding configuration. - Enhanced unit tests to validate the functionality of the `padding_side` parameter in various scenarios. * feat(processor): Add state management methods to Pi0NewLineProcessor * feat(normalization): Track normalization and unnormalization info in complementary data - Updated NormalizerProcessor and UnnormalizerProcessor to accept additional parameters for tracking normalization modes. - Enhanced the __call__ methods to store normalization and unnormalization information in the complementary data of transitions. - Added unit tests to verify the correct tracking of normalization info, including scenarios with missing stats and selective normalization keys. * feat(factory): Add preprocessor and postprocessor overrides to ProcessorConfigKwargs - Updated ProcessorConfigKwargs to include optional overrides for preprocessor and postprocessor configurations. - Enhanced the make_processor function to utilize the new overrides, allowing for more flexible processor initialization. * feat(processors): Integrate RenameProcessor into various processor configurations - Added RenameProcessor to the input steps of multiple processor functions, including make_act_processor, make_diffusion_processor, make_pi0_processor, make_sac_processor, make_tdmpc_processor, make_vqbet_processor, and make_smolvla_processor. - Consolidated normalization features from input and output into a single NormalizerProcessor for improved efficiency. - Updated the input steps to ensure compatibility with the new RenameProcessor integration. * feat(smolvla): Refactor language processing and introduce new line processor (#1658) - Removed the prepare_language method and directly accessed language tokens and masks from the batch using the OBS_LANGUAGE constant. - Added SmolVLANewLineProcessor to ensure tasks end with a newline, enhancing tokenization compatibility. - Updated the make_smolvla_processor function to include the new line processor and tokenizer processor for improved input handling. * feture(policies): add device processor (#1659) * feat(processors): Integrate DeviceProcessor into multiple processor configurations - Added DeviceProcessor to the input and output steps of various processor functions, including make_act_processor, make_diffusion_processor, make_pi0_processor, make_pi0fast_processor, make_sac_processor, make_tdmpc_processor, make_vqbet_processor, and make_smolvla_processor. - Enhanced the DeviceProcessor class with state management methods and ensured compatibility with existing processor pipelines. - Introduced unit tests for DeviceProcessor to validate functionality across different scenarios, including CPU and CUDA operations. * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * refactor(pipeline): Remove to() method for device management - Eliminated the to() method from RobotProcessor, which was responsible for moving tensor states to specified devices. - Removed associated unit tests that validated the functionality of the to() method across various scenarios. - Streamlined the pipeline code by focusing on other device management strategies. * feat(processor): Enhance DeviceProcessor with float dtype conversion - Added support for optional float dtype conversion in DeviceProcessor, allowing tensors to be converted to specified floating-point types while preserving non-float types. - Implemented validation for float dtype input and updated the processor's configuration methods to include float dtype. - Refactored tensor processing logic to streamline device movement and dtype conversion. - Introduced comprehensive unit tests to validate the new float dtype functionality across various scenarios. * feat(policies): Add new line processors and update module exports * feat(processor): Enhance batch and device processors to handle index and task_index fields - Added logic to ToBatchProcessor for unsqueezing 0D tensors for index and task_index fields, ensuring they are processed as 1D tensors. - Updated DeviceProcessor to process index and task_index fields in complementary data, preserving their tensor types and ensuring non-tensor fields remain unchanged. - Enhanced unit tests to validate the correct handling of index and task_index fields across various scenarios, including device compatibility and dtype preservation. * Add eval script * fix `q_curr` in InverseKinematicsEEToJoints to the IK solution * feat(processors): Introduce processors for various policy types - Added `make_processor` function to create processor instances for different policy types, including `tdmpc`, `diffusion`, `act`, `vqbet`, `pi0`, `pi0fast`, `sac`, and `reward_classifier`. - Implemented corresponding processor files for each policy type, encapsulating normalization and unnormalization steps. - Updated existing policies to remove direct normalization dependencies, enhancing modularity and clarity. - Enhanced test coverage to validate the integration of new processors with existing policy configurations. * refactor(learner): Remove normalization from cached image features retrieval - Simplified the retrieval of observation features by removing the normalization step from the `get_cached_image_features` method calls. - This change enhances clarity and aligns with the recent updates to policy processors. * refactor(policies): Remove unnormalization step from action predictions - Eliminated the unnormalization of actions in both `TDMPCPolicy` and `VQBeTPolicy` classes to streamline action prediction. - This change improves code clarity and aligns with recent updates to policy processors. * feat(train): Integrate preprocessor into training pipeline * refactor(train): Update preprocessor initialization to include dataset statistics * refactor(policies): Enhance processor creation and add NaN detection hook * feat(record): Integrate RobotProcessor into recording loop and update policy handling - Added support for RobotProcessor in the record_loop function to enhance data processing capabilities. - Updated the logic to reset both policy and processor when provided, ensuring proper state management. - Modified action prediction to utilize the processor, improving the overall functionality of the recording process. - Adjusted the save_checkpoint function to include preprocessor state saving, enhancing checkpointing capabilities. * feat(migration): Add script for migrating policy models with normalization layers * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * feat(migrate): Enhance migration script to create preprocessor and postprocessor for policy models - Updated the migration script to generate both a preprocessor and a postprocessor, improving the handling of normalization for training and inference. - Added functionality to convert features to PolicyFeature objects, ensuring compatibility with the new processor architecture. - Refined the extraction and removal of normalization statistics and layers, streamlining the migration process. - Improved error handling for missing mandatory configuration fields during model instantiation. * feat(migrate): Add model card generation and saving to migration script - Implemented functionality to generate and save a model card for the migrated model, including metadata such as dataset repository ID, license, and tags. - Enhanced the script to push the model card to the hub if requested, improving model documentation and accessibility. - Refactored the saving process to ensure the model card is saved locally and uploaded correctly when pushing to the hub. * feat(processor): Introduce ToBatchProcessor for handling observation batching - Added ToBatchProcessor to ensure observations have proper batch dimensions for model processing. - Implemented functionality to add batch dimensions to state and image observations as needed. - Created comprehensive unit tests to validate the processor's behavior with various tensor dimensions and types. - Ensured compatibility with existing transition keys and maintained the integrity of non-observation data. * feat(processors): Add ToBatchProcessor to multiple policy processors - Integrated ToBatchProcessor into various policy processors to handle observation batching. - Updated make functions for act, diffusion, pi0, pi0fast, sac, smolvla, tdmpc, and vqbet processors to include the new batching functionality. - Ensured consistency across all processor implementations for improved data handling. * refactor(factory): Remove unused imports and NaN detection hook from processor creation * feat(batch_processor): Enhance ToBatchProcessor to handle action batching - Updated ToBatchProcessor to add batch dimensions to actions in addition to observations. - Implemented separate methods for processing observations and actions, improving code readability. - Added comprehensive unit tests to validate action batching functionality across various tensor dimensions and types. * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * feat(factory): Enhance make_processor to support preprocessor and postprocessor configuration - Introduced ProcessorConfigKwargs TypedDict for better type safety in processor configuration. - Updated make_processor to accept preprocessor and postprocessor configuration filenames, improving flexibility in processor instantiation. - Refactored the loading of pretrained processors to utilize the new configuration options. * refactor(factory): Clean up imports in factory.py - Removed unused import of IdentityProcessor to streamline the code. * feat(migrate): Extend load_model_from_hub to include train configuration - Updated load_model_from_hub to return the train configuration alongside the model state_dict and config. - Modified main function to handle the additional train configuration when loading models from both the hub and local paths. - Adjusted dataset_repo_id extraction to utilize the train configuration for improved accuracy. * refactor(record): Rename processor parameters and update processing logic - Renamed `processor` to `preprocessor` and added `postprocessor` parameter for clarity. - Updated the `record_loop` and `predict_action` functions to utilize the new preprocessor and postprocessor, enhancing the processing flow. - Ensured compatibility with existing functionality while improving code readability. * feat(batch_processor): Add task field processing to ToBatchProcessor - Enhanced ToBatchProcessor to wrap string tasks in a list, adding batch dimensions for compatibility with model inference. - Implemented a new method for processing complementary data, ensuring that task values are correctly handled as either strings or lists of strings. - Added comprehensive unit tests to validate task processing, including edge cases and in-place mutation of complementary data. * feat(normalization): Implement IDENTITY mode for normalization and unnormalization - Enhanced NormalizerProcessor and UnnormalizerProcessor to support IDENTITY mode, allowing features to bypass normalization when specified. - Updated processing logic to check normalization modes and handle missing statistics gracefully. - Added comprehensive unit tests to validate IDENTITY mode functionality for both observations and actions, ensuring correct behavior across various scenarios. - Improved error handling for unsupported normalization modes. * fix(rebase): remove residual normalization layer: * refactor(diffusion): remove normalization layer from input processing * refactor(normalization): Remove unused state dict transformation methods and streamline imports - Eliminated the _transform_state_dict_keys and _load_as_safetensor methods from PI0Policy, simplifying the model loading process. - Cleaned up imports in modeling_pi0.py by removing log_model_loading_keys and init_logging. - Updated TDMPCPolicy and VQBeTPolicy to handle action removal from batches during offline evaluation. - Introduced hotswap_stats function in normalize_processor.py to update normalization statistics dynamically, with corresponding tests to ensure functionality. * refactor(normalization): Clean up imports in normalize_processor.py * feat(batch_processor): Add feature_contract method to ToBatchProcessor - Introduced feature_contract method that returns features without modification, maintaining the no-op behavior of the processor. - This addition enhances the flexibility of the ToBatchProcessor for future feature processing needs. * fix(dependencies): Update transformers dependency constraint to allow only versions up to 4.52.0 * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * feature(pipeline): port tokenizer pipeline for VLA (#1645) * feat(tokenizer): Introduce TokenizerProcessor for text tokenization - Added TokenizerProcessor class to handle tokenization of task strings using Hugging Face's AutoTokenizer. - Supports both string and list inputs, with customizable parameters for task key, output key, and tokenization settings. - Implemented comprehensive unit tests to validate functionality, including handling of various input scenarios and integration with RobotProcessor. - Updated types.py to include LANGUAGE feature type and modified __init__.py to register the new processor. * feat(language): Enhance language processing in TokenizerProcessor - Added OBS_LANGUAGE constant to define the observation language key. - Updated TokenizerProcessor to store tokenized task data in the observation dictionary, ensuring compatibility with the new language feature. - Introduced Pi0NewLineProcessor to append newlines to tasks for proper tokenization. - Modified tests to validate the integration of language tokens and attention masks in the observation structure. * feat(tokenizer): Add padding configuration to TokenizerProcessor - Introduced `padding_side` parameter to the TokenizerProcessor for customizable padding direction. - Updated the `make_pi0_processor` function to include the new padding configuration. - Enhanced unit tests to validate the functionality of the `padding_side` parameter in various scenarios. * feat(processor): Add state management methods to Pi0NewLineProcessor * feat(normalization): Track normalization and unnormalization info in complementary data - Updated NormalizerProcessor and UnnormalizerProcessor to accept additional parameters for tracking normalization modes. - Enhanced the __call__ methods to store normalization and unnormalization information in the complementary data of transitions. - Added unit tests to verify the correct tracking of normalization info, including scenarios with missing stats and selective normalization keys. * feat(factory): Add preprocessor and postprocessor overrides to ProcessorConfigKwargs - Updated ProcessorConfigKwargs to include optional overrides for preprocessor and postprocessor configurations. - Enhanced the make_processor function to utilize the new overrides, allowing for more flexible processor initialization. * feat(processors): Integrate RenameProcessor into various processor configurations - Added RenameProcessor to the input steps of multiple processor functions, including make_act_processor, make_diffusion_processor, make_pi0_processor, make_sac_processor, make_tdmpc_processor, make_vqbet_processor, and make_smolvla_processor. - Consolidated normalization features from input and output into a single NormalizerProcessor for improved efficiency. - Updated the input steps to ensure compatibility with the new RenameProcessor integration. * feat(smolvla): Refactor language processing and introduce new line processor (#1658) - Removed the prepare_language method and directly accessed language tokens and masks from the batch using the OBS_LANGUAGE constant. - Added SmolVLANewLineProcessor to ensure tasks end with a newline, enhancing tokenization compatibility. - Updated the make_smolvla_processor function to include the new line processor and tokenizer processor for improved input handling. * feture(policies): add device processor (#1659) * feat(processors): Integrate DeviceProcessor into multiple processor configurations - Added DeviceProcessor to the input and output steps of various processor functions, including make_act_processor, make_diffusion_processor, make_pi0_processor, make_pi0fast_processor, make_sac_processor, make_tdmpc_processor, make_vqbet_processor, and make_smolvla_processor. - Enhanced the DeviceProcessor class with state management methods and ensured compatibility with existing processor pipelines. - Introduced unit tests for DeviceProcessor to validate functionality across different scenarios, including CPU and CUDA operations. * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * refactor(pipeline): Remove to() method for device management - Eliminated the to() method from RobotProcessor, which was responsible for moving tensor states to specified devices. - Removed associated unit tests that validated the functionality of the to() method across various scenarios. - Streamlined the pipeline code by focusing on other device management strategies. * feat(processor): Enhance DeviceProcessor with float dtype conversion - Added support for optional float dtype conversion in DeviceProcessor, allowing tensors to be converted to specified floating-point types while preserving non-float types. - Implemented validation for float dtype input and updated the processor's configuration methods to include float dtype. - Refactored tensor processing logic to streamline device movement and dtype conversion. - Introduced comprehensive unit tests to validate the new float dtype functionality across various scenarios. * feat(policies): Add new line processors and update module exports * feat(processor): Enhance batch and device processors to handle index and task_index fields - Added logic to ToBatchProcessor for unsqueezing 0D tensors for index and task_index fields, ensuring they are processed as 1D tensors. - Updated DeviceProcessor to process index and task_index fields in complementary data, preserving their tensor types and ensuring non-tensor fields remain unchanged. - Enhanced unit tests to validate the correct handling of index and task_index fields across various scenarios, including device compatibility and dtype preservation. * refactor(processors): Standardize processor naming conventions - Updated processor names across various files to use a consistent "robot_preprocessor" and "robot_postprocessor" format. - Modified the make_processor functions in factory, act, diffusion, pi0, pi0fast, sac, smolvla, tdmpc, and vqbet to reflect the new naming scheme. - Enhanced the pipeline configuration to align with the updated processor names, improving clarity and maintainability. * refactor(factory): Update processor configuration and type hints - Changed return type of get_policy_class to type[PreTrainedPolicy] for improved type safety. - Enhanced make_processor function to utilize dataset_stats in processor creation for better flexibility. - Updated ProcessorConfigKwargs to include dataset_stats, allowing for more comprehensive processor configurations. - Streamlined processor initialization by removing unnecessary kwargs and ensuring clarity in processor type handling. * Fix eval and android gripper * add some tests * refactor(factory, pi0fast): Update processor function names and parameters - Renamed make_pi0_processor to make_pi0fast_processor for clarity and consistency. - Updated parameter names in the factory's make_processor function to use pretrained_model_name_or_path instead of source, enhancing readability and alignment with naming conventions. * fix(train.py) push postprocessor with preprocessor - Add preprocesser policy overrides for device and rename_map - Add rename_map to DatasetRecordConfig (record.py) * Cleanup pr * fix more git diff pr issues * add path as type in save_pretrained * small nit * [pre-commit.ci] auto fixes from pre-commit.com hooks for more information, see https://pre-commit.ci * rename test file * fix: make dataset_features/feature_contract is optional * fix tests * Encorperate pr feedback * clean up record.py * add ascii art, fix normal record * remove merge issues * fix merge * remove features * Add feedback PR * fix last 4 tests * remove features check * rename to transform_features * add transform_features * fix lekiwi eval and update eval api example --------- Signed-off-by: Adil Zouitine <adilzouitinegm@gmail.com> Signed-off-by: Pepijn <138571049+pkooij@users.noreply.github.com> Co-authored-by: Adil Zouitine <adilzouitinegm@gmail.com> Co-authored-by: pre-commit-ci[bot] <66853113+pre-commit-ci[bot]@users.noreply.github.com> Co-authored-by: Copilot <175728472+Copilot@users.noreply.github.com> Co-authored-by: Simon Alibert <75076266+aliberts@users.noreply.github.com> Co-authored-by: Michel Aractingi <michel.aractingi@huggingface.co>
![]()
![]()

![]()


![]()

Meet HopeJR – A humanoid robot arm and hand for dexterous manipulation!
Control it with exoskeletons and gloves for precise hand movements.
Perfect for advanced manipulation tasks! 🤖
 |
 |
Meet the updated SO100, the SO-101 – Just €114 per arm!
Train it in minutes with a few simple moves on your laptop.
Then sit back and watch your creation act autonomously! 🤯
See the full SO-101 tutorial here.
Want to take it to the next level? Make your SO-101 mobile by building LeKiwi!
Check out the LeKiwi tutorial and bring your robot to life on wheels.

LeRobot: State-of-the-art AI for real-world robotics
🤗 LeRobot aims to provide models, datasets, and tools for real-world robotics in PyTorch. The goal is to lower the barrier to entry to robotics so that everyone can contribute and benefit from sharing datasets and pretrained models.
🤗 LeRobot contains state-of-the-art approaches that have been shown to transfer to the real-world with a focus on imitation learning and reinforcement learning.
🤗 LeRobot already provides a set of pretrained models, datasets with human collected demonstrations, and simulation environments to get started without assembling a robot. In the coming weeks, the plan is to add more and more support for real-world robotics on the most affordable and capable robots out there.
🤗 LeRobot hosts pretrained models and datasets on this Hugging Face community page: huggingface.co/lerobot
Examples of pretrained models on simulation environments
 |
 |
 |
| ACT policy on ALOHA env | TDMPC policy on SimXArm env | Diffusion policy on PushT env |
Installation
LeRobot works with Python 3.10+ and PyTorch 2.2+.
Environment Setup
Create a virtual environment with Python 3.10 and activate it, e.g. with miniconda:
conda create -y -n lerobot python=3.10
conda activate lerobot
When using miniconda, install ffmpeg in your environment:
conda install ffmpeg -c conda-forge
NOTE: This usually installs
ffmpeg 7.Xfor your platform compiled with thelibsvtav1encoder. Iflibsvtav1is not supported (check supported encoders withffmpeg -encoders), you can:
- [On any platform] Explicitly install
ffmpeg 7.Xusing:conda install ffmpeg=7.1.1 -c conda-forge
- [On Linux only] Install ffmpeg build dependencies and compile ffmpeg from source with libsvtav1, and make sure you use the corresponding ffmpeg binary to your install with
which ffmpeg.
Install LeRobot 🤗
From Source
First, clone the repository and navigate into the directory:
git clone https://github.com/huggingface/lerobot.git
cd lerobot
Then, install the library in editable mode. This is useful if you plan to contribute to the code.
pip install -e .
NOTE: If you encounter build errors, you may need to install additional dependencies (
cmake,build-essential, andffmpeg libs). On Linux, run:sudo apt-get install cmake build-essential python3-dev pkg-config libavformat-dev libavcodec-dev libavdevice-dev libavutil-dev libswscale-dev libswresample-dev libavfilter-dev. For other systems, see: Compiling PyAV
For simulations, 🤗 LeRobot comes with gymnasium environments that can be installed as extras:
For instance, to install 🤗 LeRobot with aloha and pusht, use:
pip install -e ".[aloha, pusht]"
Installation from PyPI
Core Library: Install the base package with:
pip install lerobot
This installs only the default dependencies.
Extra Features: To install additional functionality, use one of the following:
pip install 'lerobot[all]' # All available features
pip install 'lerobot[aloha,pusht]' # Specific features (Aloha & Pusht)
pip install 'lerobot[feetech]' # Feetech motor support
Replace [...] with your desired features.
Available Tags: For a full list of optional dependencies, see: https://pypi.org/project/lerobot/
Weights & Biases
To use Weights and Biases for experiment tracking, log in with
wandb login
(note: you will also need to enable WandB in the configuration. See below.)
Visualize datasets
Check out example 1 that illustrates how to use our dataset class which automatically downloads data from the Hugging Face hub.
You can also locally visualize episodes from a dataset on the hub by executing our script from the command line:
python -m lerobot.scripts.visualize_dataset \
--repo-id lerobot/pusht \
--episode-index 0
or from a dataset in a local folder with the root option and the --local-files-only (in the following case the dataset will be searched for in ./my_local_data_dir/lerobot/pusht)
python -m lerobot.scripts.visualize_dataset \
--repo-id lerobot/pusht \
--root ./my_local_data_dir \
--local-files-only 1 \
--episode-index 0
It will open rerun.io and display the camera streams, robot states and actions, like this:
Our script can also visualize datasets stored on a distant server. See python -m lerobot.scripts.visualize_dataset --help for more instructions.
The LeRobotDataset format
A dataset in LeRobotDataset format is very simple to use. It can be loaded from a repository on the Hugging Face hub or a local folder simply with e.g. dataset = LeRobotDataset("lerobot/aloha_static_coffee") and can be indexed into like any Hugging Face and PyTorch dataset. For instance dataset[0] will retrieve a single temporal frame from the dataset containing observation(s) and an action as PyTorch tensors ready to be fed to a model.
A specificity of LeRobotDataset is that, rather than retrieving a single frame by its index, we can retrieve several frames based on their temporal relationship with the indexed frame, by setting delta_timestamps to a list of relative times with respect to the indexed frame. For example, with delta_timestamps = {"observation.image": [-1, -0.5, -0.2, 0]} one can retrieve, for a given index, 4 frames: 3 "previous" frames 1 second, 0.5 seconds, and 0.2 seconds before the indexed frame, and the indexed frame itself (corresponding to the 0 entry). See example 1_load_lerobot_dataset.py for more details on delta_timestamps.
Under the hood, the LeRobotDataset format makes use of several ways to serialize data which can be useful to understand if you plan to work more closely with this format. We tried to make a flexible yet simple dataset format that would cover most type of features and specificities present in reinforcement learning and robotics, in simulation and in real-world, with a focus on cameras and robot states but easily extended to other types of sensory inputs as long as they can be represented by a tensor.
Here are the important details and internal structure organization of a typical LeRobotDataset instantiated with dataset = LeRobotDataset("lerobot/aloha_static_coffee"). The exact features will change from dataset to dataset but not the main aspects:
dataset attributes:
├ hf_dataset: a Hugging Face dataset (backed by Arrow/parquet). Typical features example:
│ ├ observation.images.cam_high (VideoFrame):
│ │ VideoFrame = {'path': path to a mp4 video, 'timestamp' (float32): timestamp in the video}
│ ├ observation.state (list of float32): position of an arm joints (for instance)
│ ... (more observations)
│ ├ action (list of float32): goal position of an arm joints (for instance)
│ ├ episode_index (int64): index of the episode for this sample
│ ├ frame_index (int64): index of the frame for this sample in the episode ; starts at 0 for each episode
│ ├ timestamp (float32): timestamp in the episode
│ ├ next.done (bool): indicates the end of an episode ; True for the last frame in each episode
│ └ index (int64): general index in the whole dataset
├ episode_data_index: contains 2 tensors with the start and end indices of each episode
│ ├ from (1D int64 tensor): first frame index for each episode — shape (num episodes,) starts with 0
│ └ to: (1D int64 tensor): last frame index for each episode — shape (num episodes,)
├ stats: a dictionary of statistics (max, mean, min, std) for each feature in the dataset, for instance
│ ├ observation.images.cam_high: {'max': tensor with same number of dimensions (e.g. `(c, 1, 1)` for images, `(c,)` for states), etc.}
│ ...
├ info: a dictionary of metadata on the dataset
│ ├ codebase_version (str): this is to keep track of the codebase version the dataset was created with
│ ├ fps (float): frame per second the dataset is recorded/synchronized to
│ ├ video (bool): indicates if frames are encoded in mp4 video files to save space or stored as png files
│ └ encoding (dict): if video, this documents the main options that were used with ffmpeg to encode the videos
├ videos_dir (Path): where the mp4 videos or png images are stored/accessed
└ camera_keys (list of string): the keys to access camera features in the item returned by the dataset (e.g. `["observation.images.cam_high", ...]`)
A LeRobotDataset is serialised using several widespread file formats for each of its parts, namely:
- hf_dataset stored using Hugging Face datasets library serialization to parquet
- videos are stored in mp4 format to save space
- metadata are stored in plain json/jsonl files
Dataset can be uploaded/downloaded from the HuggingFace hub seamlessly. To work on a local dataset, you can specify its location with the root argument if it's not in the default ~/.cache/huggingface/lerobot location.
Evaluate a pretrained policy
Check out example 2 that illustrates how to download a pretrained policy from Hugging Face hub, and run an evaluation on its corresponding environment.
We also provide a more capable script to parallelize the evaluation over multiple environments during the same rollout. Here is an example with a pretrained model hosted on lerobot/diffusion_pusht:
python -m lerobot.scripts.eval \
--policy.path=lerobot/diffusion_pusht \
--env.type=pusht \
--eval.batch_size=10 \
--eval.n_episodes=10 \
--policy.use_amp=false \
--policy.device=cuda
Note: After training your own policy, you can re-evaluate the checkpoints with:
python -m lerobot.scripts.eval --policy.path={OUTPUT_DIR}/checkpoints/last/pretrained_model
See python -m lerobot.scripts.eval --help for more instructions.
Train your own policy
Check out example 3 that illustrates how to train a model using our core library in python, and example 4 that shows how to use our training script from command line.
To use wandb for logging training and evaluation curves, make sure you've run wandb login as a one-time setup step. Then, when running the training command above, enable WandB in the configuration by adding --wandb.enable=true.
A link to the wandb logs for the run will also show up in yellow in your terminal. Here is an example of what they look like in your browser. Please also check here for the explanation of some commonly used metrics in logs.
<img src="https://raw.githubusercontent.com/huggingface/lerobot/main/media/wandb.png" alt="WandB logs example">
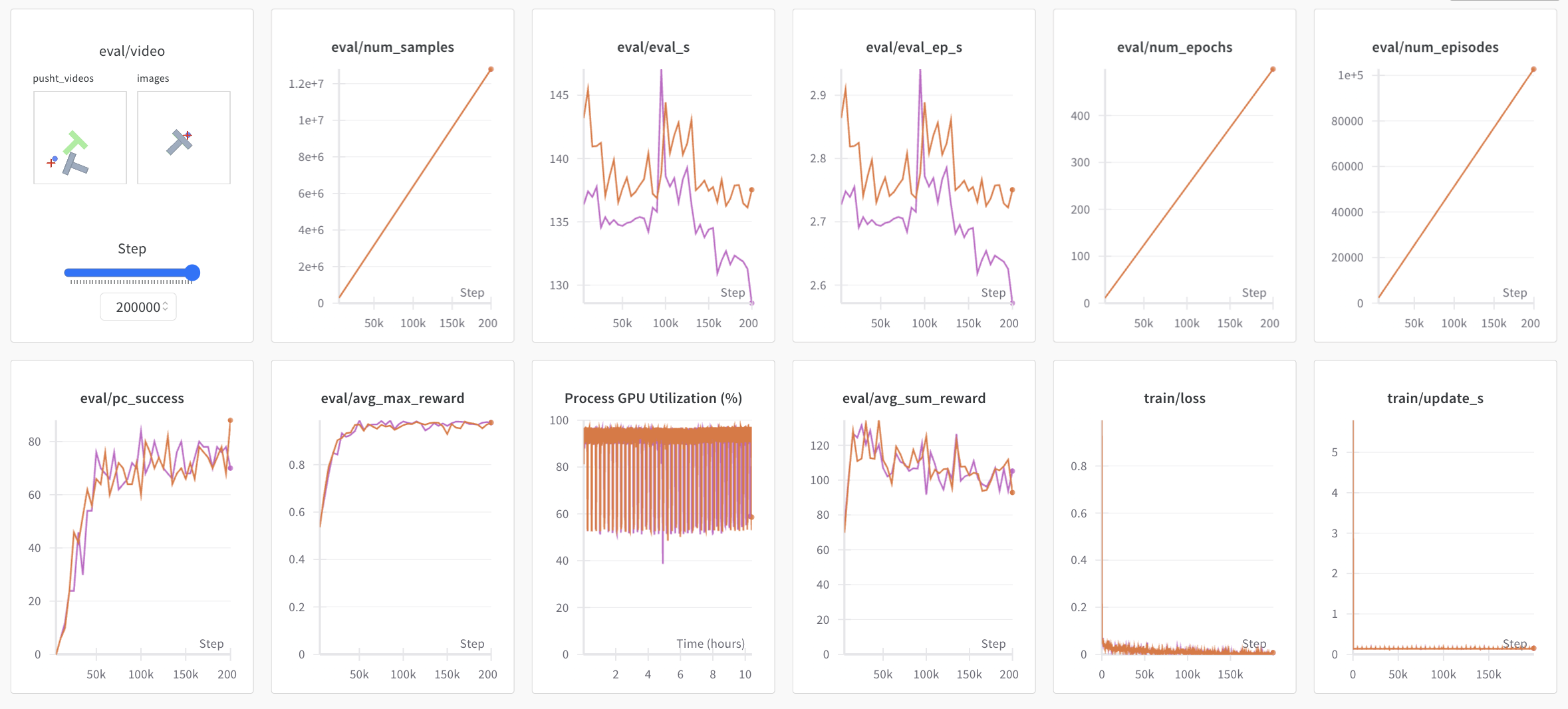{kind=link}
Note: For efficiency, during training every checkpoint is evaluated on a low number of episodes. You may use --eval.n_episodes=500 to evaluate on more episodes than the default. Or, after training, you may want to re-evaluate your best checkpoints on more episodes or change the evaluation settings. See python -m lerobot.scripts.eval --help for more instructions.
Reproduce state-of-the-art (SOTA)
We provide some pretrained policies on our hub page that can achieve state-of-the-art performances. You can reproduce their training by loading the config from their run. Simply running:
python -m lerobot.scripts.train --config_path=lerobot/diffusion_pusht
reproduces SOTA results for Diffusion Policy on the PushT task.
Contribute
If you would like to contribute to 🤗 LeRobot, please check out our contribution guide.
Add a pretrained policy
Once you have trained a policy you may upload it to the Hugging Face hub using a hub id that looks like ${hf_user}/${repo_name} (e.g. lerobot/diffusion_pusht).
You first need to find the checkpoint folder located inside your experiment directory (e.g. outputs/train/2024-05-05/20-21-12_aloha_act_default/checkpoints/002500). Within that there is a pretrained_model directory which should contain:
config.json: A serialized version of the policy configuration (following the policy's dataclass config).model.safetensors: A set oftorch.nn.Moduleparameters, saved in Hugging Face Safetensors format.train_config.json: A consolidated configuration containing all parameters used for training. The policy configuration should matchconfig.jsonexactly. This is useful for anyone who wants to evaluate your policy or for reproducibility.
To upload these to the hub, run the following:
huggingface-cli upload ${hf_user}/${repo_name} path/to/pretrained_model
See eval.py for an example of how other people may use your policy.
Acknowledgment
- The LeRobot team 🤗 for building SmolVLA Paper, Blog.
- Thanks to Tony Zhao, Zipeng Fu and colleagues for open sourcing ACT policy, ALOHA environments and datasets. Ours are adapted from ALOHA and Mobile ALOHA.
- Thanks to Cheng Chi, Zhenjia Xu and colleagues for open sourcing Diffusion policy, Pusht environment and datasets, as well as UMI datasets. Ours are adapted from Diffusion Policy and UMI Gripper.
- Thanks to Nicklas Hansen, Yunhai Feng and colleagues for open sourcing TDMPC policy, Simxarm environments and datasets. Ours are adapted from TDMPC and FOWM.
- Thanks to Antonio Loquercio and Ashish Kumar for their early support.
- Thanks to Seungjae (Jay) Lee, Mahi Shafiullah and colleagues for open sourcing VQ-BeT policy and helping us adapt the codebase to our repository. The policy is adapted from VQ-BeT repo.
Citation
If you want, you can cite this work with:
@misc{cadene2024lerobot,
author = {Cadene, Remi and Alibert, Simon and Soare, Alexander and Gallouedec, Quentin and Zouitine, Adil and Palma, Steven and Kooijmans, Pepijn and Aractingi, Michel and Shukor, Mustafa and Aubakirova, Dana and Russi, Martino and Capuano, Francesco and Pascal, Caroline and Choghari, Jade and Moss, Jess and Wolf, Thomas},
title = {LeRobot: State-of-the-art Machine Learning for Real-World Robotics in Pytorch},
howpublished = "\url{https://github.com/huggingface/lerobot}",
year = {2024}
}